

Combineer Screaming Frog met Google Search Console
Eén van mijn favoriete functies in Screaming Frog is dat je heel eenvoudig en snel lijsten kunt crawlen. Dit combineer ik dan met gegevens uit Google Search Console. Samen sporen ze de issues op die er echt toe doen en de moeite waard zijn om op te lossen. Zo verspil je geen tijd meer aan fouten die er eigenlijk niet (meer) zijn. Hoe je dat doet? Hier leg ik je uit hoe je twee belangrijke lijsten uit Search Console eenvoudig controleert met Screaming Frog. Daarna laat ik je zien hoe je een crawl moet configureren om er nog meer waardevolle data uit te halen. Dus, ben je er klaar voor om je SEO-leven makkelijker te maken?
Lijst met ‘Niet gevonden (404)’ uit Google Search Console controleren
In Google Search Console vind je onder Pagina-indexering ‘Waarom pagina’s niet worden geïndexeerd’. Eén van die lijsten met redenen is ‘Niet gevonden (404)’. Nu hebben wij daar weleens vol verbazing naar zitten kijken. “Hoe kan die lijst zo lang zijn, we hebben toch alles opgelost?” Wat blijkt? Google Search Console loopt regelmatig achter bij de werkelijkheid. En dan is Screaming Frog een uitkomst.
- Je exporteert de lijst ‘Niet gevonden (404)’ uit Search Console naar een sheet
- Vervolgens kopieer je de lijst met 404’s, zodat deze op je klembord staat
- Open Screaming Frog
- Kies onder ‘Mode’ voor de optie ‘List’
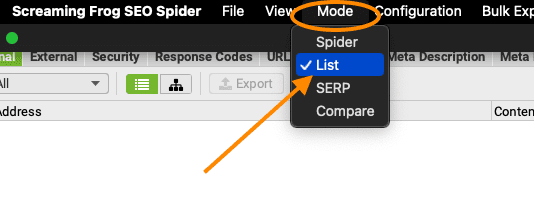
- Nu klik je onder ‘Upload’ op ‘Paste’ en dan worden de URLs vanaf je klembord gelijk in de lijst gezet.
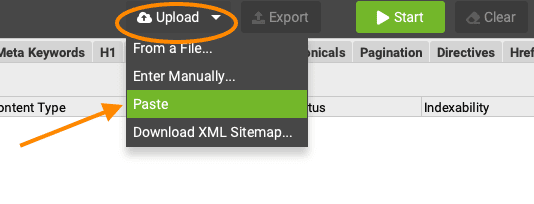
- Klik op OK en Screaming Frog start met de crawl van je lijst.
- Crawl klaar? Zowel in de kolom ‘Status Code’ als in de ‘Overview’ aan de rechterkant zie je dat een aantal URLs al een redirect heeft of zelfs helemaal geen 404 is. In mijn voorbeeld heeft slechts 70% van de lijst op dit moment een status code 404.
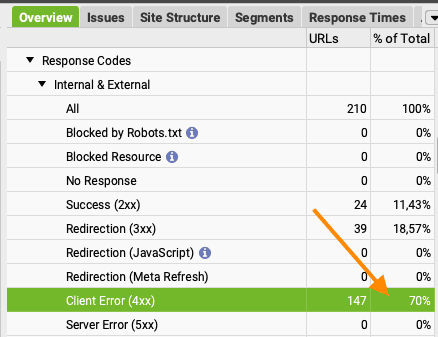
- Filter nu op de 404’s. Dit zijn je echte, actuele 404’s. Los deze op.
- Klaar? Ga dan terug naar Google Search Console en klik op ‘Oplossing valideren’.
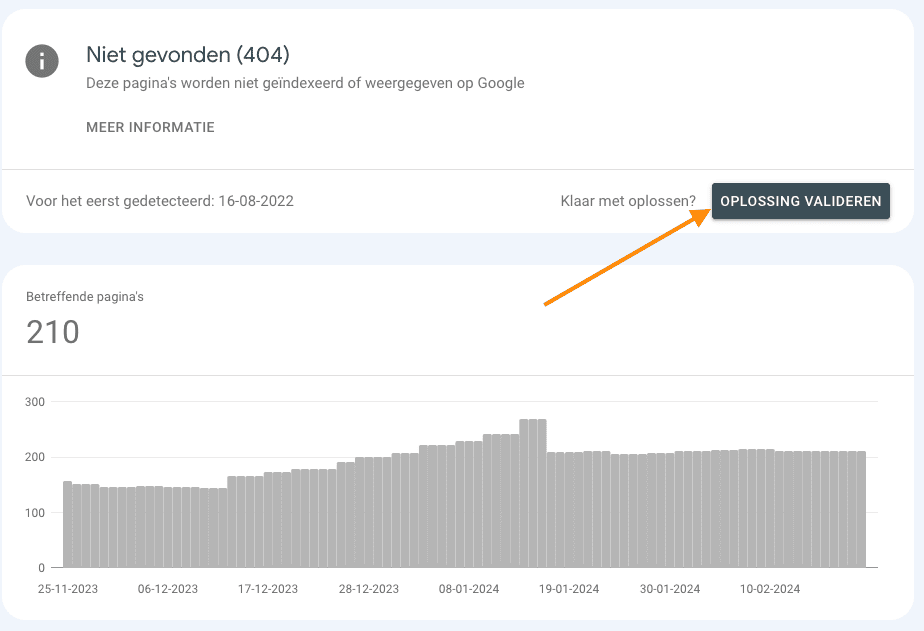
Dit is een handige en snelle manier om dubbel werk en onterechte redirects te voorkomen. Met als grootste beloning natuurlijk dat je de lijst met 404’s ziet afnemen.
Lijst met ‘- momenteel niet geïndexeerd’ uit Google Search Console checken
Kijk je ook weleens naar de lijsten ‘Gecrawld / gevonden – momenteel niet geïndexeerd’? En denk je dan wel eens, als je een mooie URL ziet: “Dit is een goed blog, waarom wordt deze niet geïndexeerd?” Zo heb ik weleens fanatiek geprobeerd om een URL in de index te krijgen die daar helemaal niet in hoefde. Uiteindelijk bleek namelijk dat ik de URL zonder trailing slash (/ aan het eind) zag, terwijl de URL met trailing slash al netjes was geïndexeerd. Dit check je op de volgende manier:
- Exporteer de lijst ‘Gecrawld – momenteel niet geïndexeerd’ en /of ‘Gevonden -momenteel niet geïndexeerd uit Search Console naar een sheet.
- Kopieer de lijst, zodat deze op je klembord staat.
- Volg stap 3 t/m 6 zoals hierboven genoemd (onder 404’s)
- Zodra de crawl klaar is, check je welke URLs daadwerkelijk indexeerbaar zijn. In dit voorbeeld zit op 75 % van de URLs een 301-redirect. Die hoeven dus helemaal niet in de index. Maar let op! In de lijst met Status Code 200 heeft een aantal URLs een canonical tag. Deze hoeven dus ook niet in de index opgenomen.
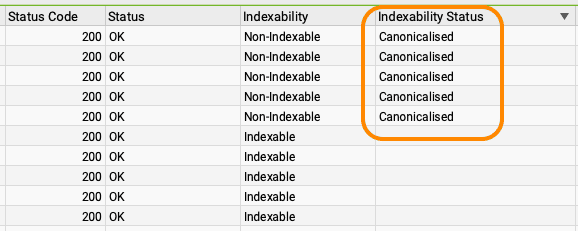
Nu heb je een lijst met pagina’s die indexeerbaar zijn, maar om een of andere reden niet in de index worden opgenomen. Controleer of dit echt goede pagina’s zijn en vraag waar nodig handmatig indexatie aan. Extra interne links leggen wil ook nog weleens helpen.
Een crawl in Screaming Frog configureren
Hieronder leg ik uit welke stappen ik neem voordat ik een crawl in Screaming Frog start. Zo krijg je namelijk nog meer gegevens waar je dieper in kunt duiken tijdens je analyse. Je moet even weten welke checkboxes je moet aanvinken. Als je dit eenmaal goed hebt staan, haal je nog meer bruikbare data uit Search Console.
- Kies onder ‘Mode’ voor ‘Spider’
- Ga via het menu ‘Configuration’ naar ‘Crawl’
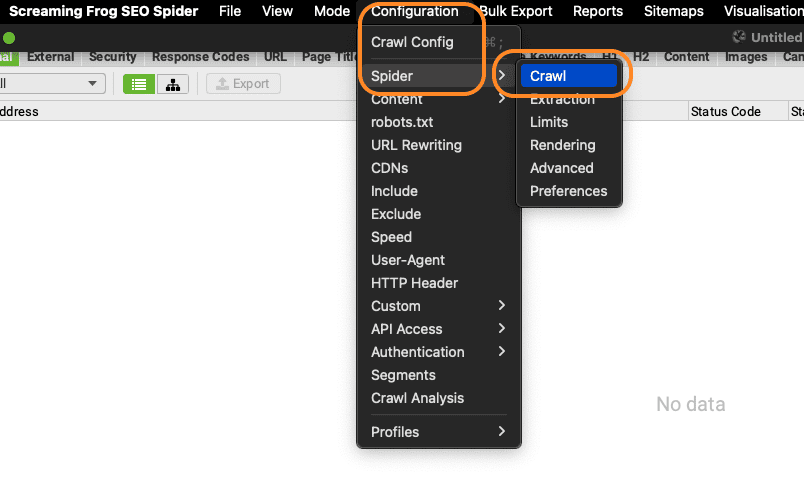
Hier vink je aan ‘Auto Discover XML Sitemaps via robots.txt’. Check wel even of je sitemap ook echt genoemd wordt in de robotst.txt. Zo niet, vink dan ‘Crawl These Sitemaps’ aan en vul de sitemap handmatig in. Zo weet je zeker dat alle pagina’s uit je sitemap worden meegenomen in de crawl.
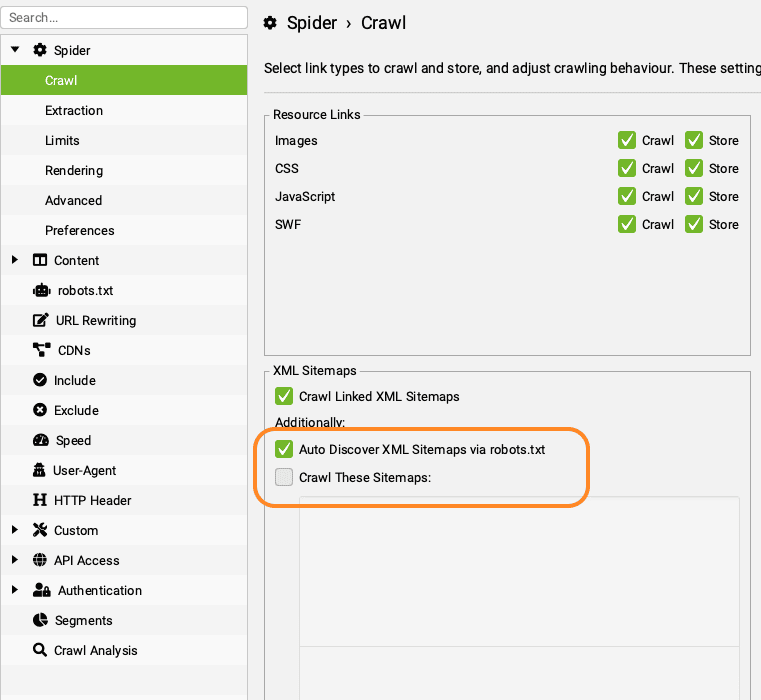
- Vervolgens ga je naar het onderdeel ‘Content’ en vervolgens ‘Duplicates’
- Vink ‘Enable Near Duplicates’ aan.
- Standaard staat de drempel op 90%, maar ik verlaag hem altijd naar 80%. Zo ontdek je pagina’s die sterk op elkaar lijken. Dit kan namelijk een verklaring zijn waarom een URL weinig verkeer krijgt. En dit helpt je ook weer bij het opschonen van je content.
- Ga nu naar het onderdeel ‘API Access’
- Hier koppel je Google Analytics 4
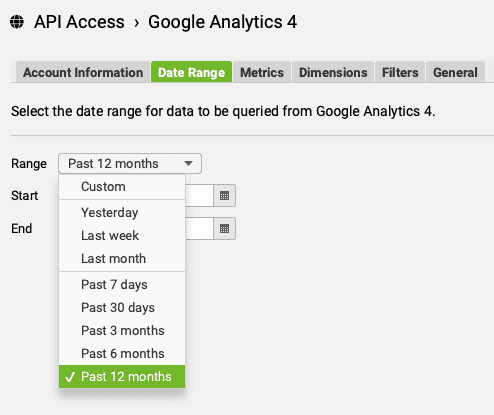
- Ga naar het tabje ‘Date Range’. Standaard staat deze op 30 dagen, maar als je net in het laagseizoen zit, zie je misschien ten onrechte weinig verkeer. Zet de Range daarom op ‘Past 12 months’.
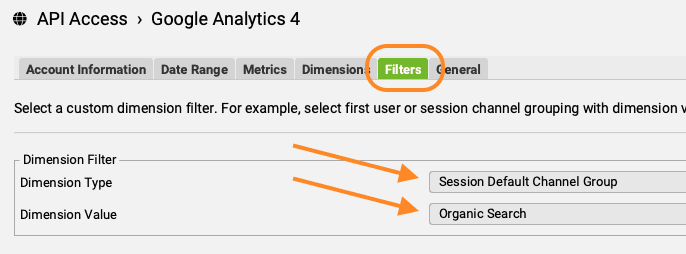
- Eventueel ga je nog naar het tabje ‘Filters’. Hier kun je aangeven dat je alleen data uit Organic Search wil meenemen.
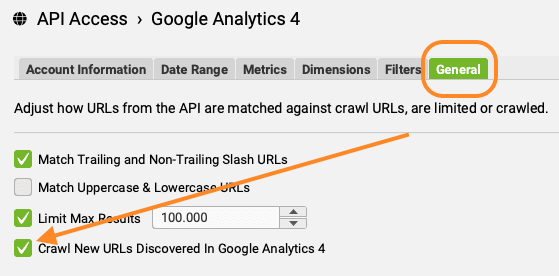
- Ga naar het tabje ‘General’. Vink de checkbox ‘Crawl New URLs Discovered in Google Analytics 4’ aan.
- Vergeet niet rechtsonder op OK te klikken om je koppeling op te slaan.
- Koppel nu Google Search Console.
- Ga naar het tabje ‘Search Analytics’ en pas de Range aan naar 12 maanden
- In datzelfde tabje staat de checkbox voor ‘Crawl New URLs Discovered in Google Search Console’. Deze vink je ook aan.
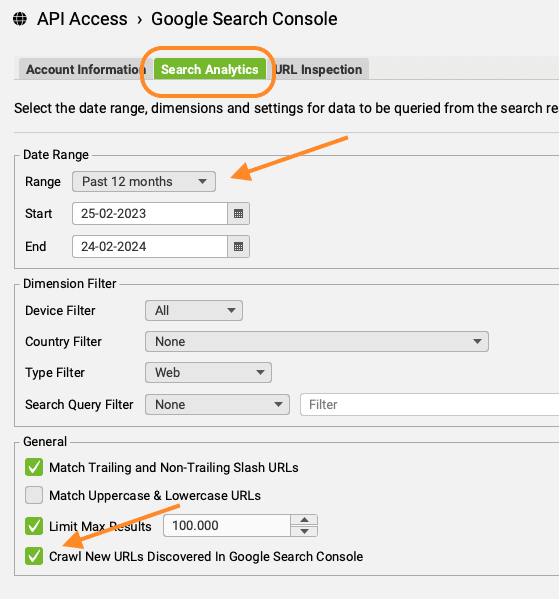
- Tot slot ga je naar het onderdeel ‘Crawl Analysis’
- Zet hier het vinkje aan bij ‘Auto-analyse at End of Crawl’ aan. Screaming Frog gaat dan onder ‘Overview’ informatie vullen over bijvoorbeeld Near Duplicates en Orphan Search Console pages. Dat is heel handig voor verdere analyse.

- Vul nu nog je URL in en ga iets leuks voor jezelf doen terwijl Screaming Frog al het werk doet.
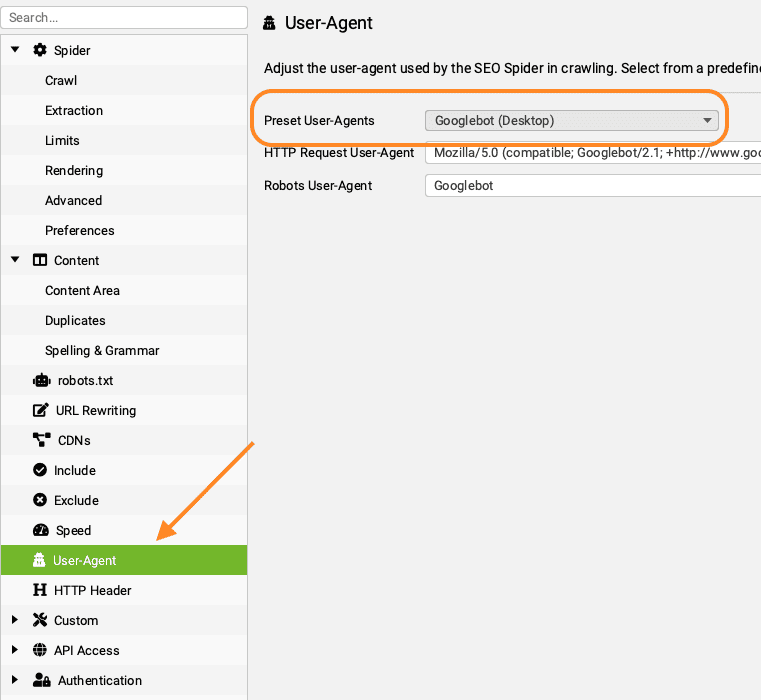
Help, Screaming Frog crawlt mijn site niet
Lukt het niet om een website te crawlen met Screaming Frog? Krijg je alleen de homepage terug of Status Code 429 – Too Many Requests? Wijzig dan de User Agent van Screaming Frog naar Google. Er zijn namelijk websites die standaard een flinke lijst crawlers, waaronder Screaming Frog, uitsluiten via de robots.txt. Of de server ziet Screaming Frog als een gebruiker die teveel verzoeken stuurt. Door te doen alsof je Google bent, omzeil je deze beperkingen. Je vindt de instellingen voor User Agent in het menu onder ‘Configuration’.
Data uit Google Search Console en Analytics combineren
Als je van plan bent om oude content op te schonen, kun je in Google Search Console kijken welke URLs in de afgelopen 12 maanden niet of nauwelijks kliks hebben opgeleverd. Kliks op een zoekresultaat zijn echter niet het hele verhaal. Een bezoeker kan ook op een andere pagina binnenkomen en dan alsnog doorklikken naar de ‘slechte’ URL. En soms zie je dat een URL met weinig kliks toch omzet heeft opgeleverd, omdat het een conversiegerichte long tail zoekterm bevat.
Hierboven heb ik uitgelegd hoe je een complete crawl configureert. Als je vervolgens al je data exporteert naar Google Sheets of Excel, krijg je met filters al snel inzicht in URLs die helemaal niets opleveren en URLs die toch waardevol zijn.
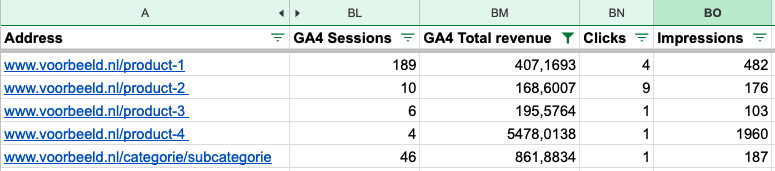
Van die laatste is het interessant om te onderzoeken waarom ze weinig kliks krijgen. Misschien moet je de Meta Description aanpassen of de focus op een andere zoekterm leggen.
Orphan Search Console Pages
Een orphan page is een pagina die geen interne links krijgt. De pagina is dus niet opgenomen in de navigatie en krijgt ook geen link vanaf een andere pagina. Als zo’n pagina wel vertoningen doet in het zoekresultaat, kan deze interessant zijn voor SEO.
- Om Orphan Search Console Pages te ontdekken, stel je een crawl in zoals hierboven genoemd.
- Vergeet niet om de checkbox voor ‘Crawl New URLs Discovered in Google Search Console’ aan te vinken en ‘Auto-analyse at End of Crawl’.
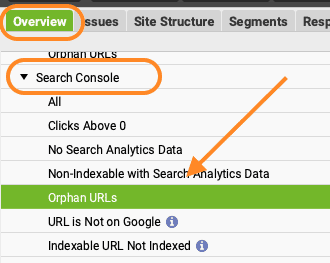
- Heeft Screaming Frog de crawl afgerond? Dan vind je onder ‘Reports’ het rapport ‘Orphan Pages’. Hiermee exporteer je alle orphans naar een sheet (ook orphan sitemap pages en orphan GA4 pages).
- Filter in je sheet de kolom ‘Source’ op ‘GSC’ om alle orphans in Google Search Console te ontdekken.
- Liever in Screaming Frog zelf kijken? Klik dan in de ‘Overview’ onder ‘Search Console’ op ‘Orphan URLs.
Heb je orphans gevonden? En krijgen deze vertoningen in Google Search Console? Dan loont het de moeite om die pagina interne links te geven, bijvoorbeeld vanuit relevante blogs. Niet interessant voor SEO? Verwijder de pagina dan en geef deze een 301-redirect naar een andere, relevante pagina.
Je kunt nog veel meer met Screaming Frog
In onze blogs en kennisbank vind je nog veel meer SEO-adviezen waarbij Screaming Frog je vriend is. Bijvoorbeeld:
- Ontdek redirect loops en redirect chains (Mariska)
Een website beheren betekent ook wijzigen, verplaatsen en verwijderen. Natuurlijk plaats je altijd netjes een 301-redirect, maar op termijn kunnen daar fouten in ontstaan, zoals redirects die naar elkaar verwijzen (loops) of die steeds weer naar een nieuwe redirect verwijzen (chains). Hiervoor kijk je in het Redirects Report. - Breng alle URLs in kaart voor het herstructureren van je URL-structuur (Ivo)
Als je een crawl combineert met je sitemap, GA4 en Search Console, zoals hierboven uitgelegd, krijg je een vrij compleet beeld van alle URLs die er zijn en die dus gemigreerd moeten worden. - Identificeer broken links en los ze op (Jesse)
Hiervoor klik je op de tab ‘Response Codes’ en vervolgens zet je het filter op ‘Client Error (4XX)’ Of ga naar ‘Bulk Export / Response Codes / Internal / Internal Client Error (4xx) Inlinks’ om de gegevens te downloaden naar een sheet.
Heb je meer dan duizenden URLs om te crawlen? Dan wordt Screaming Frog nogal traag.
Kijk in dat geval eens naar andere SEO tools om je website te crawlen, zoals Ahrefs, Lumar (voorheen Deepcrawl) en ContentKing.
Als SEO bureau zijn wij experts in het optimaliseren van websites voor zoekmachines en bieden we uitgebreide trainingen aan. Ben je geïnteresseerd in het volgen van een SEO training of wil je dieper duiken in de wereld van zoekmachineoptimalisatie met een Online SEO training? Neem dan contact op met ons. Wij bieden praktische trainingen aan die je helpen om jouw website beter te laten ranken. We delen graag onze kennis en expertise om je vaardigheden in SEO te versterken.
Mochten er nog andere vragen zijn, neem dan contact met ons op. Onze technische SEO specialisten kijken graag met je mee
Share
Categorieën
Heb je vragen?
Neem contact op! :) wij helpen je graag verder met al je SEO vragen
SEO vraag stellenMis het niet
Meld je aan voor onze nieuwsbrief en mis geen enkele SEO tip
"*" geeft vereiste velden aan









