
Het nieuwe crawl stats rapport in Search Console
Als SEO specialisten hebben we een haat-liefde verhouding met Google (ik generaliseer even). De zoekmachine haalt soms functies weg waar we zo gehecht aan waren. Denk aan zoekterminformatie in Google Analytics (waar ik in een ver verleden als eens een jankblog over schreef) of op dit moment de ‘indexering aanvragen’ knop in Search Console. Maar meer dan ooit houden we ook van Google. In de eerste plaats omdat organisch verkeer nog steeds in potentie veel verkeer oplevert. Maar ook omdat Google de laatste tijd mooie en bruikbare functionaliteiten aan Search Console toevoegt. Op 24 november 2020 stond er ineens een herboren ‘crawl stats report’ in Search Console plus een aankondiging van Google zelf. In dit artikel lees je wat het nieuwe crawl stats rapport inhoudt en wat je er mee kunt.
Het crawl stats report is niet nieuw, want was ook aanwezig in good old Webmaster Tools in het verleden. Maar deze versie is een flinke verbetering!
Waarom zijn crawlstatistieken belangrijk?
Een zoekresultaat in Google komt niet zomaar tot stand, daar gaat een heel proces aan vooraf. Of eigenlijk drie processen:
- Crawlen: het ontdekken van URLs
- Indexeren: het interpreteren van informatie die op de URLs aanwezig is en het opslaan van deze URLs
- Ranken: het ordenen van resultaten om zo het beste antwoord te kunnen geven op een zoekvraag
Het crawlproces is fundamenteel: een URL die niet gecrawld wordt komt ook niet in Google te staan. Het nieuwe Crawl stats rapport in Search Console geeft je informatie over dit crawlproces, zodat je dit wellicht kunt verbeteren.
Wat houdt het crawl stats rapport in?
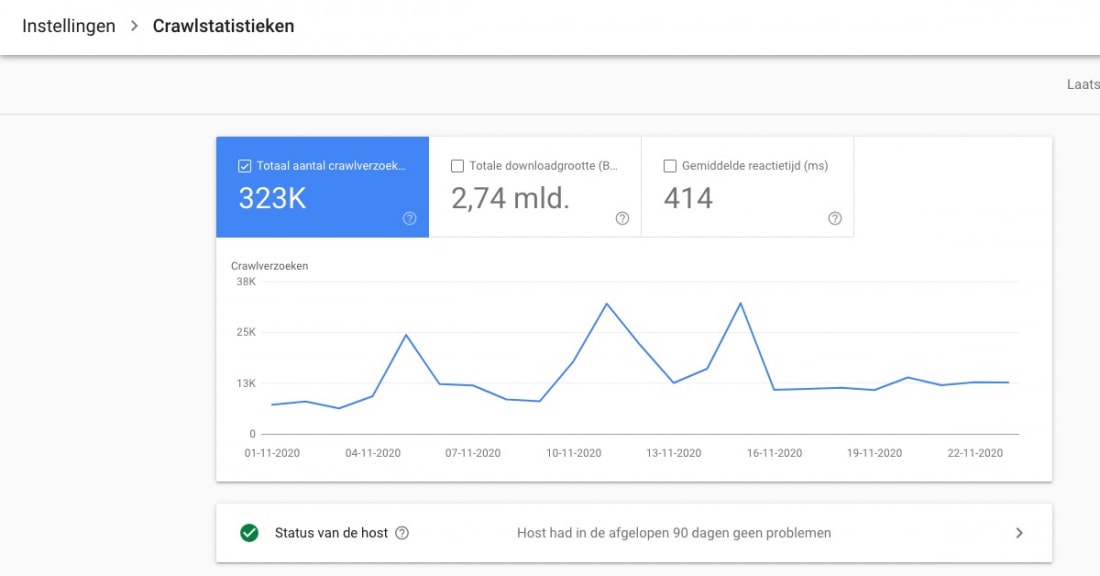
Het crawl stats rapport vind je in Search Console onder Instellingen. De overview ziet er als volgt uit:

De overview laat standaard drie weken data zien en valt uiteen in:
- Het totaal aantal crawlverzoeken tijdens deze periode
- De downloadgrootte in deze periode: het totaal aantal bytes dat gedownload is
- De gemiddelde reactietijd bij een crawl om de paginacontent op te halen
Dit verschilt overigens niet veel van de oude versie van crawl stats (uit Webmaster Tools). Op het tonen van alle drie de statistieken in één overzicht na.
Nieuw: host status
Een nieuw onderdeel is de status van de host. Als Google problemen ondervindt in bijvoorbeeld het ophalen van het Robots.txt bestand of problemen heeft ervaren in het crawlen van je website komt dit hier te staan.

Nieuw: uitsplitsingen crawlverzoeken
Het is voor website eigenaren en SEO specialisten van belang om te weten wat de crawlverzoeken zijn geweest en hoe de verhoudingen zijn hierin. Er zijn vier uitsplitsingen: crawlverzoeken per statuscode, per bestandstype, per doel en per GoogleBot type.
Uitsplitsing per reactie (statuscode)
Deze uitsplitsing geeft je een goed beeld van de statuscodes waar GoogleBot tijdens het crawlen tegenaan loopt. Het draait (vanuit ons perspectief) vooral om verhouding: zie je hier hoge percentages bij statuscodes die je liever niet hebt? Dan is er werk aan de winkel. In onderstaand screenshot zien we bijvoorbeeld 60% van de URLs die een status OK geven, maar ook 13% die een status ‘anders’ geven. Je kunt op elke statuscode doorklikken, zodat je voorbeelden krijgt van URLs.
Het is nu lastig om aan te geven hoe de verhoudingen moeten zijn in dit overzicht. Maar ik zou toch zeker het aantal URLs met of een status 200 OK of een status 3xx qua aantal boven de 90% zien.

Uitsplitsing per bestandstype
Deze uitsplitsing geeft je een beeld van het type bestanden dat Google heeft gedownload. Dit is waardevol, maar draait ook weer om de verhoudingen. Van oudsher hebben we als SEO specialisten voorkeur voor zoveel mogelijk HTML. Het aantal websites dat JavaScript gebruikt is echter drastisch gestegen in de afgelopen jaren. Als je procentueel veel JavaScript ziet in dit overzicht moet je misschien na gaan denken hoe je toch HTML kunt gaan gebruiken (al dan niet alleen voor de zoekmachine en niet voor de gebruiker). Onderstaand screenshot laat een situatie zien waarin het aantal HTML bestanden relatief laag is (Ander bestandstype = 31% van het totaal aantal gedownloade bestanden).

Als we hier op doorklikken zien we voorbeelden van deze URLs:

De andere twee uitsplitsingen
De andere twee uitsplitsingen zijn minder interessant (in onze optiek). In de uitsplitsing ‘per doel’ zie je de verhouding tussen crawlverzoeken voor bestaande URLs (Vernieuwen) en nieuwe URLs (Vindbaarheid). De laatste uitsplitsing laat zien welk type GoogleBot het crawlverzoek heeft gedaan.
Crawl stats: 3 praktische toepassingen
Het crawl stats rapport bevat veel informatie over het web crawling van Google. De kunst is om deze informatie ook om te zetten in acties. Een drietal toepassingen van het crawl stats rapport zijn bijvoorbeeld:
1. De verhouding 404s, 301s en 5XX fouten verbeteren
Een 404 URL (niet gevonden) kan SEO waarde vertegenwoordigen, maar dat hoeft niet. Als dit wel het geval is, dan wil je de URL een 301 redirect geven of weer herstellen. Heeft de 404 geen waarde? Dan wil je dat Google op een gegeven moment de URL niet meer crawlt. Een 500 error (server error) is ook iets wat je zo snel mogelijk moet oplossen, want de server stelt GoogleBot dan niet in staat om een pagina te crawlen. Ga voor een gezonde verhouding tussen 200 OK URLs, redirects en foutmeldingen (404 en 500). Analyseer de foutmeldingen, verbeter ze en zorg dat je naar de 95% met je 200 OK URLs en redirects.

2. Het crawlen van URLs bij een nieuw domein
Het migreren naar een ander domein of het live zetten van een nieuwe website geeft vaak veel onduidelijkheid. Vindt Google de nieuwe pagina’s wel snel genoeg? Zien we veel fouten tijdens een migratie? Allemaal onderdelen waarbij dit crawl stats rapport van pas gaat komen. Denk bijvoorbeeld aan:
- Het constateren van veel 404 URLs tijdens een migratie
- Een Robots.txt file die niet benaderbaar is (te zien in het ‘host status rapport’)
- Zien dat de gemiddelde reactietijd voor een crawlverzoek veel te hoog ligt (in vergelijking met andere websites)
3. Monitoring op crawl fouten
Als je website problemen heeft met het beschikbaar maken van Robots.txt of problemen ondervindt in het crawlen van je website (DNS issues, server issues), dan zie je dat terug in het rapport. De monitoring is niet realtime helaas.
Nadelen van het crawl stats rapport
We hebben in bovenstaande tekst al veel genoemd over de voordelen en toepassingen van het crawl stats rapport, maar er kleven ook een aantal (flinke) nadelen aan:
- Google noemt voorbeelden van URLs in een beperkt aantal. Je gaat dus nooit een totale overview van crawlstatistieken krijgen in dit rapport. Daarvoor zul je echt aan de slag moeten met log file analyse.
- Search Console loopt vaak een aantal dagen achter. Grote veranderingen constateer je daardoor misschien 3 dagen te laat. Als je echt crawlproblemen hebt wil je dat direct oplossen.
- Het is niet mogelijk om je datumbereik aan te passen. Voor de overview heb je drie weken data en voor de hoststatus informatie over de afgelopen 90 dagen.
- Crawl stats is (voor zover ik kon zien) niet beschikbaar voor subfolder properties in Search Console. Je kunt dus geen crawl stats zien voor bijvoorbeeld een Domein.com/NL subfolder.
Een gegeven paard
Toch mogen we best blij zijn dat Google deze functionaliteit ook aan Search Console heeft toegevoegd. Check ook de documentatie van Google zelf hierover. En ga vooral eens zelf in Search Console kijken (onder Instellingen) hoe de crawl stats van je website er uit zien! We delen graag onze technische SEO checklist met je. Als je onderstaande gegevens invult ontvang je de checklist direct in je mailbox.





